Transformers, not the cinematic giants but the groundbreaking AI model that has reshaped the landscape of machine learning. Imagine having an intelligent companion capable of effortlessly translating languages, just a glimpse of the extraordinary capabilities that the Transformer model brings to the table. Today, we embark on an enlightening journey to understand how Transformers emerged and, like true superheroes, have revolutionized the way machines learn.
The Birth of Transformers:
Think of Transformers as the superheroes of deep learning, initially gaining recognition for their prowess in language translation. Their rise to fame mirrored that of a social media sensation, capturing the attention of tech communities on platforms like Hacker News and Reddit.
Attention and its Evolution:
Central to the Transformers’ power is the concept of “Attention.” Initially utilized for language translation, Transformers took this idea and elevated it, surpassing even Google’s Neural Machine Translation model. Their secret weapon? Parallelization – the ability to perform tasks rapidly and efficiently.
Meet the Transformers – Model Components:
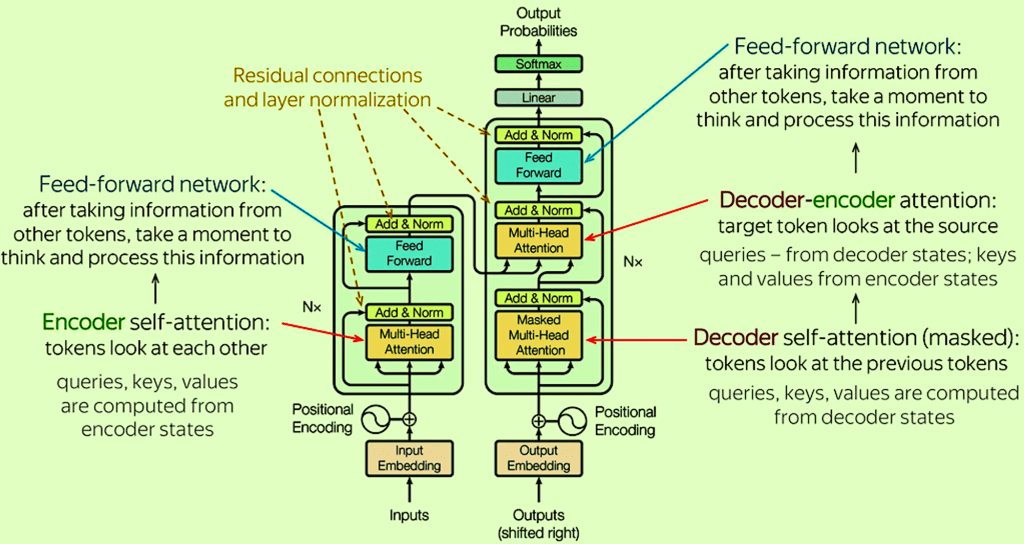
Envision Transformers as a mysterious black box, housing fascinating components. It’s akin to a magical chest containing encoding and decoding parts with interconnected elements that orchestrate seamless operations.
Encoding and Decoding Magic:
Inside the Transformer’s magical box, encoders and decoders act as stacks of identical sub-layers. These sub-layers, equipped with self-attention and feed-forward neural networks, contribute to the enchantment of parallel processing, ensuring lightning-fast operations.
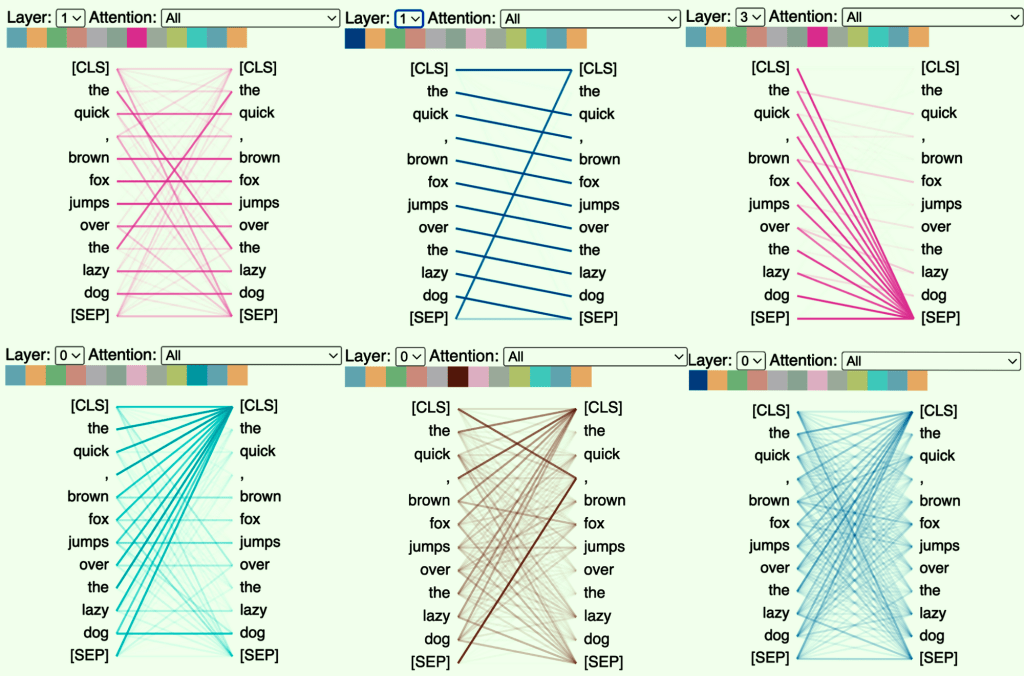
Self-Attention Mechanism:
Picture reading a sentence, and your Transformer friend can comprehend the context through self-attention. This mechanism allows the model to associate words intelligently, ensuring a deeper understanding of the text.
Calculating Self-Attention:
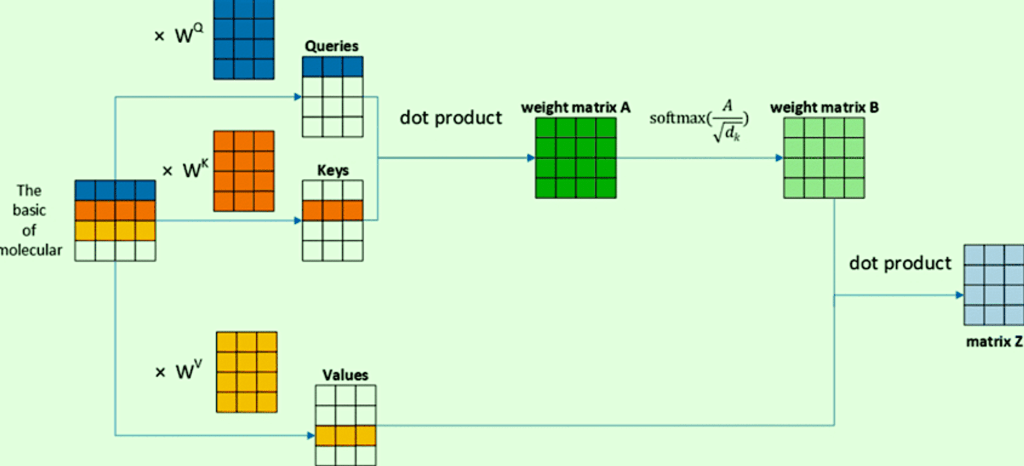
Self-attention involves creating special vectors for each word – query, key, and value. These vectors act as secret codes facilitating the model’s focus. The scoring mechanism, softmax normalization, and a weighted sum culminate in the ultimate self-attention output.
Matrix Calculation of Self-Attention:
To enhance efficiency, Transformers employ matrix calculations, allowing them to perform complex operations at remarkable speeds. Multi-headed attention is an added bonus, enabling the model to focus on different positions simultaneously.
Positional Encoding:
Transformers maintain order using positional encoding vectors, like a guiding map ensuring each word’s rightful place in a sequence. This ensures that no word gets lost in translation.
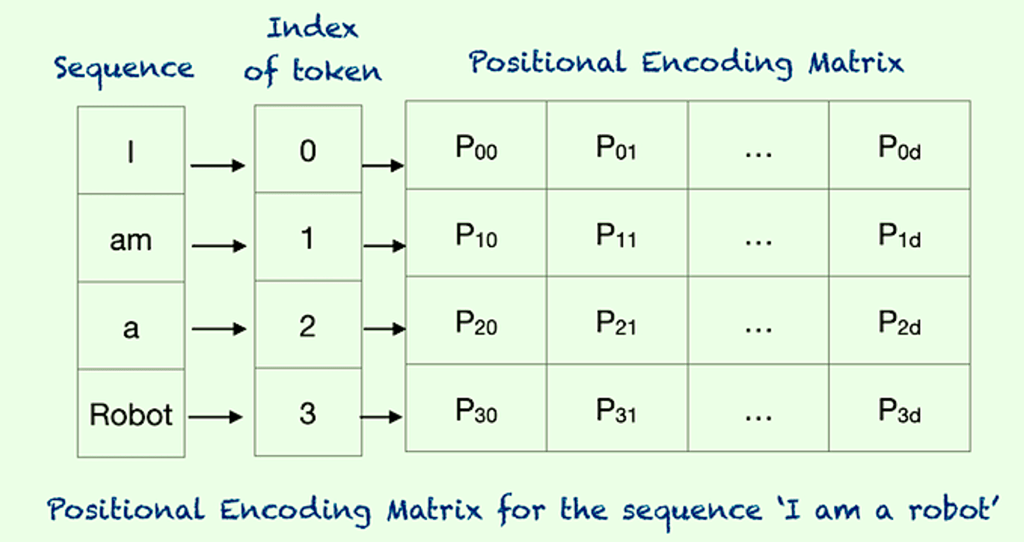
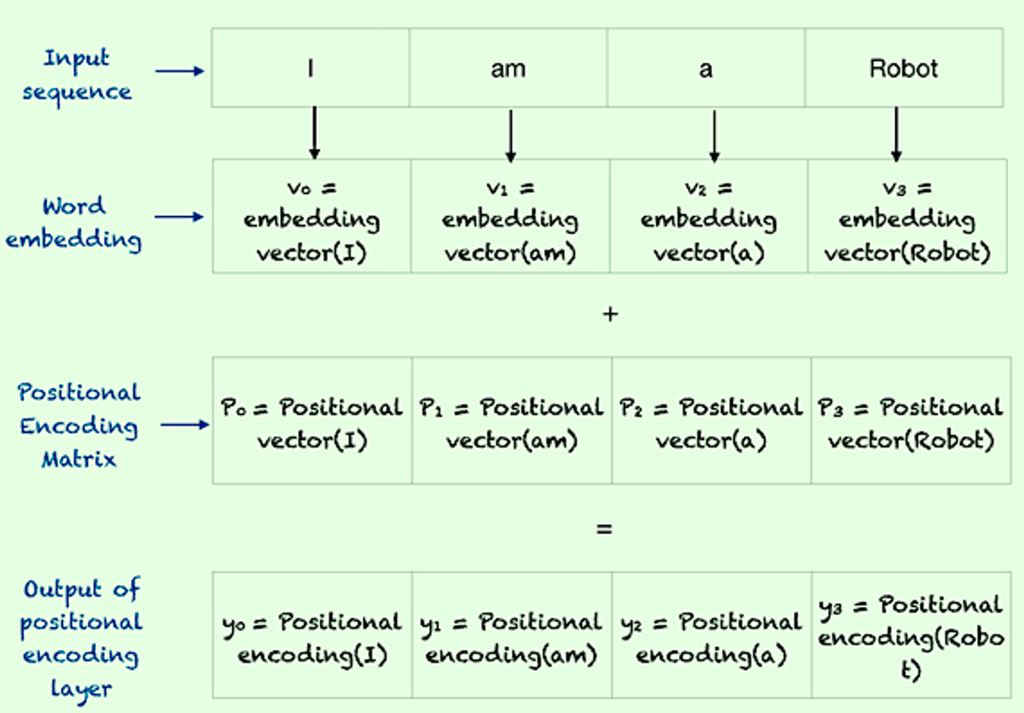
Residuals and Layer Normalization:
Every superhero requires stability. In the Transformer world, sub-layers have backups – residuals and layer normalization act as safety nets, maintaining balance in the system.
Decoding Phase:
The decoding phase resembles a puzzle where the model processes the top encoder’s output into attention vectors for each decoder. The clever self-attention layers in the decoder focus only on earlier positions in the output sequence.
The Grand Finale – Linear and Softmax Layer:
As the Transformer journey concludes, the decoder stack produces a vector transformed into a logits vector. The softmax layer works its magic, turning logits into probabilities and unveiling the final output word – the climax of our superhero movie.
Training Adventure:
Transformers undergo rigorous training, akin to empowering a superhero. The process involves a forward pass, comparisons, one-hot encoding, and a loss function, acting as a coach to optimize the model.
The Quest for Perfection – Loss Function and Training Objective:
The loss function serves as a judge, comparing the model’s output with desired translations. Training aims for superhero-level accuracy, aligning the model’s output perfectly with target translations.
Greedy Decoding vs. Beam Search:
Exploring decoding strategies, greedy decoding chooses the most likely word at each step, while beam search considers multiple options, refining the selection as the story unfolds.
In Conclusion:
Transformers emerge as the superheroes of AI, transforming the way machines comprehend and process information. Their secret ingredients, such as self-attention and parallel processing, make them the stars of the deep learning universe. Understanding the magic behind their encoding, decoding, and training processes unveils the potential they hold across various domains. Welcome to the enchanting world of Transformers – where technology meets magic!
The Business Transformation:
In the contemporary business landscape, companies are leveraging the transformative power of the Transformer model. From enhancing language processing capabilities to optimizing data analysis and decision-making, Transformers have become indispensable tools. Their ability to understand intricate patterns, process vast amounts of information simultaneously, and adapt to dynamic scenarios positions them as catalysts for innovation. Businesses, armed with the prowess of Transformers, are rewriting the narrative of efficiency, intelligence, and strategic advantage in the competitive market landscape. As the era of AI continues to unfold, the Transformers stand as beacons guiding businesses towards unprecedented possibilities and transformation.
